
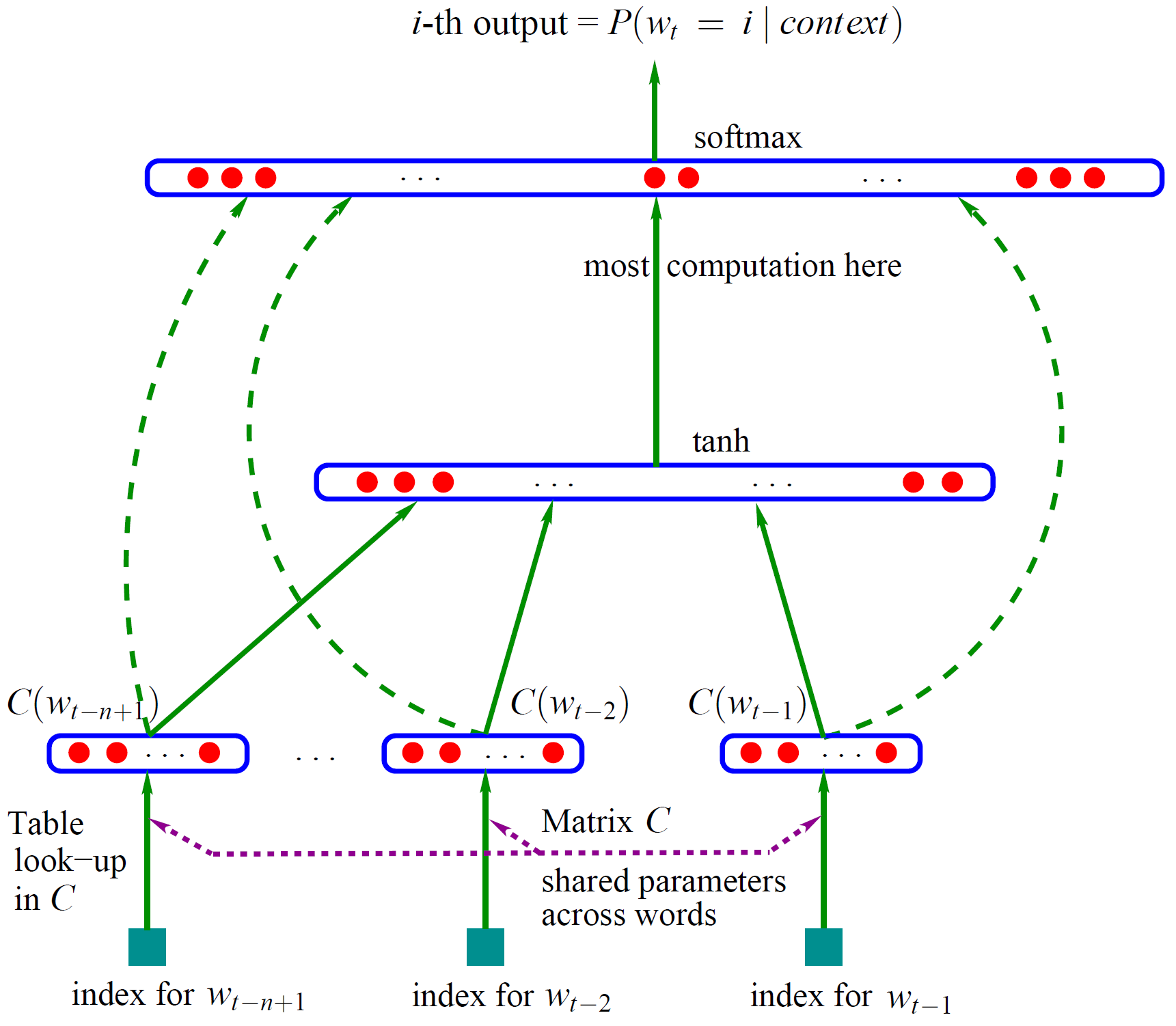
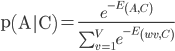
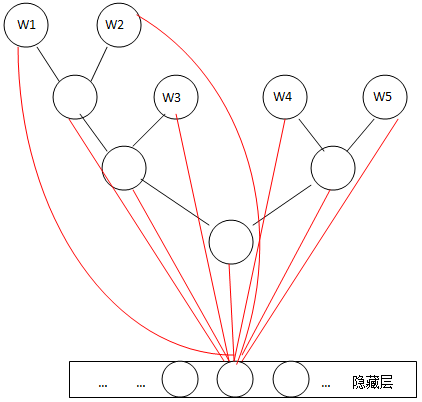
 笔记主要 记录三部分内容。第一部分记录词向量的概念和训练方法,第二部分记录如何用哈夫曼树加速网络的训练,第三部分记录word2vec的功能和实现方法。内容整理于网络。词向量词向量是一种低维实数向量。这种向量一般长成这个样子:[0.792,
−0.177, −0.107, 0.109, −0.542, ...]。维度以 50 维和 100
维比较常见。1. 词向量的来历 Distributed representation 最早是 Hinton 在 1986 年的论文《Learning
distributed representations of concepts》中提出的。...
笔记主要 记录三部分内容。第一部分记录词向量的概念和训练方法,第二部分记录如何用哈夫曼树加速网络的训练,第三部分记录word2vec的功能和实现方法。内容整理于网络。词向量词向量是一种低维实数向量。这种向量一般长成这个样子:[0.792,
−0.177, −0.107, 0.109, −0.542, ...]。维度以 50 维和 100
维比较常见。1. 词向量的来历 Distributed representation 最早是 Hinton 在 1986 年的论文《Learning
distributed representations of concepts》中提出的。...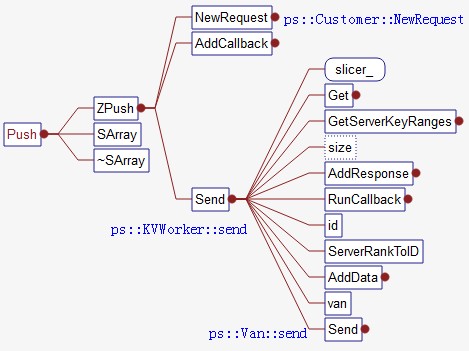 ps-lite是一个异步通信的参数服务器。主要提供push,pull,wait操作。ps-lite底层通信采用ZMQ实现。ZMQ是一个简单好用的传输层,像框架一样的一个socket library,他使得Socket编程更加简单、简洁和性能更高。是一个消息处理队列库,可在多个线程、内核和主机盒之间弹性伸缩。ps-lite中van封装了通信操作。整体结构postoffice类对van进行了管理,管理了customer的信息,提供worker和server的id转换和查询。postoffice类以单例模式出现。customer类主要维护了request和response的状态,其中的tracker...
ps-lite是一个异步通信的参数服务器。主要提供push,pull,wait操作。ps-lite底层通信采用ZMQ实现。ZMQ是一个简单好用的传输层,像框架一样的一个socket library,他使得Socket编程更加简单、简洁和性能更高。是一个消息处理队列库,可在多个线程、内核和主机盒之间弹性伸缩。ps-lite中van封装了通信操作。整体结构postoffice类对van进行了管理,管理了customer的信息,提供worker和server的id转换和查询。postoffice类以单例模式出现。customer类主要维护了request和response的状态,其中的tracker...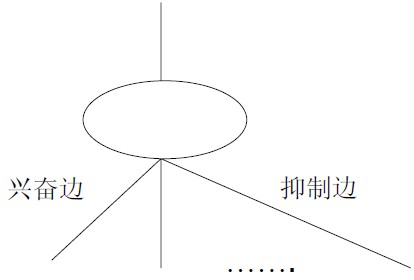
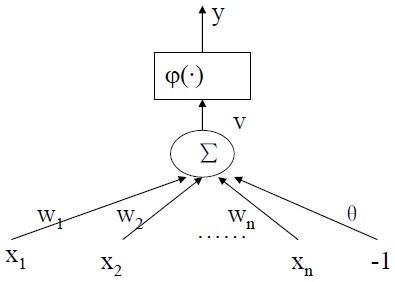
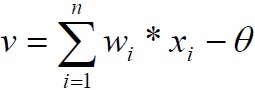 M-P模型 1943年McCulloch和Pitts发表文章,提出M-P模型。描述了一个简单的人工神经元模型的活动是服从二值(兴奋和抑制)变化的。总结了神经元的基本生理特性,提出了神经元的数学描述和网络的结构方法。——标志神经计算时代的开始神经元的输入有两种类型:兴奋边/抑制边;神经元的输出有两种状态, 兴奋/抑制;如果一条抑制边处于激活状态, 则神经元处于抑制状态;如果没有抑制边处于激活状态, 则当兴奋边的数目超过一个阈值时, 神经元处于兴奋状态, 否则处于抑制状态;特点边的权值都为固定值1, 无法调整;阈值;输出是0/1;一票否决;改进统一兴奋边和抑制边边的权值都为固定值1 -> 权...
M-P模型 1943年McCulloch和Pitts发表文章,提出M-P模型。描述了一个简单的人工神经元模型的活动是服从二值(兴奋和抑制)变化的。总结了神经元的基本生理特性,提出了神经元的数学描述和网络的结构方法。——标志神经计算时代的开始神经元的输入有两种类型:兴奋边/抑制边;神经元的输出有两种状态, 兴奋/抑制;如果一条抑制边处于激活状态, 则神经元处于抑制状态;如果没有抑制边处于激活状态, 则当兴奋边的数目超过一个阈值时, 神经元处于兴奋状态, 否则处于抑制状态;特点边的权值都为固定值1, 无法调整;阈值;输出是0/1;一票否决;改进统一兴奋边和抑制边边的权值都为固定值1 -> 权...
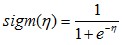
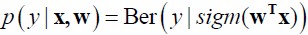 产生式分类器和判别式分类器产生式分类器:对联合分布p(x,y)建模– 产生:能从联合分布p(x,y)中产生数据– (朴素)贝叶斯分类器– LDA/QDA判别式分类器:直接对p(y|x)建模– Logistic回归– 感知机/神经元网络– SVMlogistic回归 logistic回归是对线性回归的扩展,它在线性回归的结果上再利用sigmod函数进行了一次映射。用函数表示成。其中WT *X是前面提到的线性回归的表达式,sigm是sigmod函数,形式为。sigmod函数是一个S形函数,它将线性回归的结结果映射到(0,1)区间。 这里我们只讨论类别是二值的分类。所以目标变量y服从伯努...
产生式分类器和判别式分类器产生式分类器:对联合分布p(x,y)建模– 产生:能从联合分布p(x,y)中产生数据– (朴素)贝叶斯分类器– LDA/QDA判别式分类器:直接对p(y|x)建模– Logistic回归– 感知机/神经元网络– SVMlogistic回归 logistic回归是对线性回归的扩展,它在线性回归的结果上再利用sigmod函数进行了一次映射。用函数表示成。其中WT *X是前面提到的线性回归的表达式,sigm是sigmod函数,形式为。sigmod函数是一个S形函数,它将线性回归的结结果映射到(0,1)区间。 这里我们只讨论类别是二值的分类。所以目标变量y服从伯努...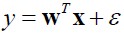
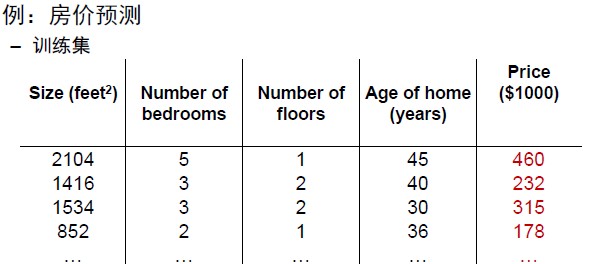
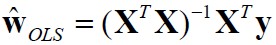 线性回归介绍 线性回归是利用数理统计中的回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。我们假设有n维特征,用公式表示为y=f(X)+ε.其中X是一个n+1维的向量,用点积形式表示为,w和x都是n+1维向量,其中n维是特征,最后1维是一个常数,或者叫截距项。我们要计算的就是这个w向量,w成为权重向量,有了w,根据公式就可以计算出y。 上图给出了一个房价预测的例子。房价预测就是用前面的四列特征,计算出房子大体的价格。也就是我们要求一个公式price=a*x1+b*x2+c*x3+d*x4+e的一个公式,使这个公式在训练集上误差最小。求得一个w向量(a,b,c...
线性回归介绍 线性回归是利用数理统计中的回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。我们假设有n维特征,用公式表示为y=f(X)+ε.其中X是一个n+1维的向量,用点积形式表示为,w和x都是n+1维向量,其中n维是特征,最后1维是一个常数,或者叫截距项。我们要计算的就是这个w向量,w成为权重向量,有了w,根据公式就可以计算出y。 上图给出了一个房价预测的例子。房价预测就是用前面的四列特征,计算出房子大体的价格。也就是我们要求一个公式price=a*x1+b*x2+c*x3+d*x4+e的一个公式,使这个公式在训练集上误差最小。求得一个w向量(a,b,c...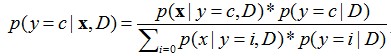
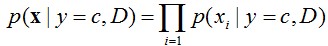
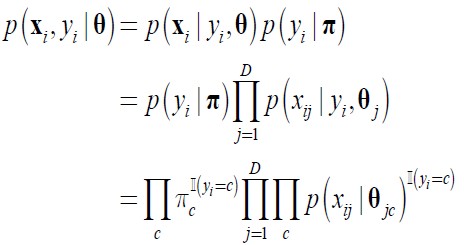 1. 朴素贝叶斯分类器 朴素贝叶斯分类是一种十分简单的分类算法,朴素贝叶斯根据给定的特征向量(若干个特征写成一行),求解在所以特征值都出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。用公式表示为y=c表示类别为c,粗体x表示一个特征向量,D是指当前数据集,因为学习是在某数据集的条件下。 可以看出,求某个类别在某些条件下出现的概率,使用的是贝叶斯公式,第一章已经提到。并且,公式的分母其实都一样,所以公式的左端正比于公式的右端分子,即每次只计算分子,哪个类别的分子大,就预测为哪个类别。从分子我们可以看出,大体上需要计算两个东西,一个是在某个类别时特征向量X出现的...
1. 朴素贝叶斯分类器 朴素贝叶斯分类是一种十分简单的分类算法,朴素贝叶斯根据给定的特征向量(若干个特征写成一行),求解在所以特征值都出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。用公式表示为y=c表示类别为c,粗体x表示一个特征向量,D是指当前数据集,因为学习是在某数据集的条件下。 可以看出,求某个类别在某些条件下出现的概率,使用的是贝叶斯公式,第一章已经提到。并且,公式的分母其实都一样,所以公式的左端正比于公式的右端分子,即每次只计算分子,哪个类别的分子大,就预测为哪个类别。从分子我们可以看出,大体上需要计算两个东西,一个是在某个类别时特征向量X出现的...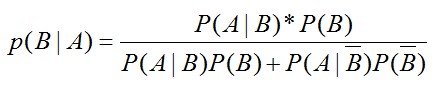
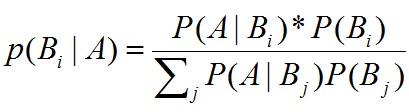
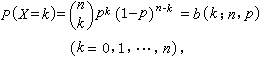 零. 开篇序言 一个学期结束了,期末匆匆忙忙的开发了这个博客系统,当时壮志雄雄的说,等我博客上线了,我一定要把这学期学的东西整理成博客,第一个文集就叫机器学习。25号考完了机器学习就赖在床上一整周,甚至博客系统有些东西都没开发完,囧。直到前天才强打精神,算是大体上把博客开发完成了,虽然有些边边角角还是需要继续修的,不过发了几篇博客感觉还是不错的,赞一个。 前天昨天今天把以前一些个小玩意稍稍整理了一下发了几篇博客,语言都不完全,完全是先占个坑。以后慢慢的补,一方面是为了测试博客,一方面是先列个大纲。 这个文集不仅是机器学习这一门课程的内容整理,还参考了相关的其他几门课程...
零. 开篇序言 一个学期结束了,期末匆匆忙忙的开发了这个博客系统,当时壮志雄雄的说,等我博客上线了,我一定要把这学期学的东西整理成博客,第一个文集就叫机器学习。25号考完了机器学习就赖在床上一整周,甚至博客系统有些东西都没开发完,囧。直到前天才强打精神,算是大体上把博客开发完成了,虽然有些边边角角还是需要继续修的,不过发了几篇博客感觉还是不错的,赞一个。 前天昨天今天把以前一些个小玩意稍稍整理了一下发了几篇博客,语言都不完全,完全是先占个坑。以后慢慢的补,一方面是为了测试博客,一方面是先列个大纲。 这个文集不仅是机器学习这一门课程的内容整理,还参考了相关的其他几门课程...