
官方教程地址http://stedolan.github.io/jq/tutorial/
我们以github上jq项目最新5条评论的JSON数据为例。获取数据如下:
curl 'https://api.github.com/repos/stedolan/jq/commits?per_page=5'
用 jq '.'即可:
curl 'https://api.github.com/repos/stedolan/jq/commits?per_page=5' | jq '.'
结果:
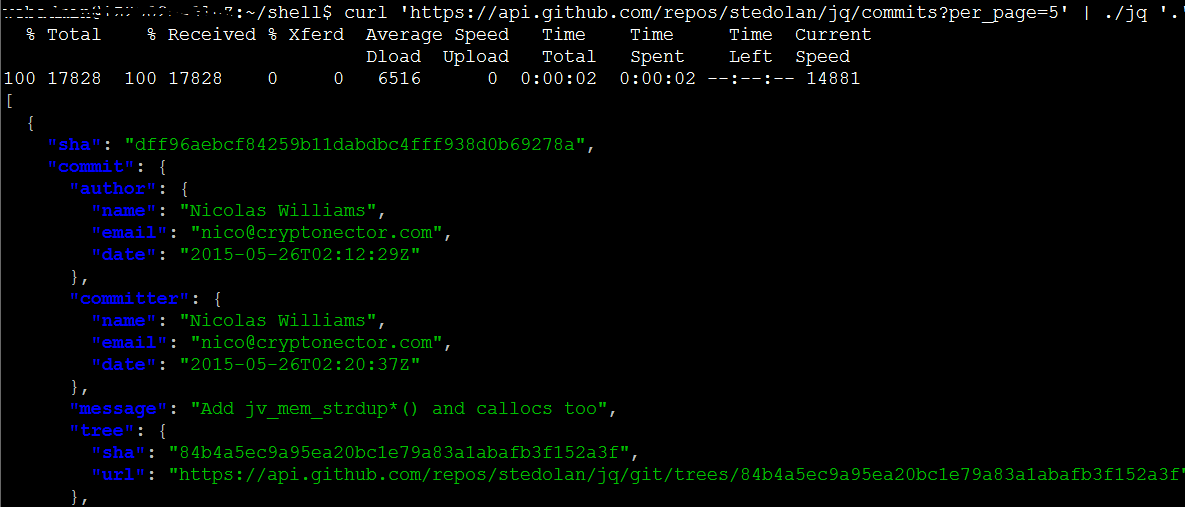
这里的评论内容比较多,我们现在想拿第一个评论。
curl 'https://api.github.com/repos/stedolan/jq/commits?per_page=5' | jq '.[0]'
我们已经拿到了一条完整的评论内容。但我们真正关心的只是评论内容和用户名,下面来获取这两项内容。
在剩下的命令中,我将不写出curl这条命令,因为内容和上面一样。
jq '.[0] | {message: .commit.message, name: .commit.committer.name}'结果:
{ "name": "Stephen Dolan", "message": "Merge pull request #162 from stedolan/utf8-fixes\n\nUtf8 fixes. Closes #161"}我们可以看到,已经拿到了想要的内容,并且已经按我们自己定义的格式显示了。
这里 | 后面的内容是以前面的内容为输入的, .commit 中的 . 就是指 .[0] 中的内容。
jq '.[] | {message: .commit.message, name: .commit.committer.name}'这里 .[] 获取的是数组中的所有项。
我们看到,结果是一个个独立的JSON对象,如何把结果组合成一个数组呢?
jq '[.[] | {message: .commit.message, name: .commit.committer.name}]'结果:
[
{ "name": "Stephen Dolan", "message": "Merge pull request #162 from stedolan/utf8-fixes\n\nUtf8 fixes. Closes #161"
},
{ "name": "Stephen Dolan", "message": "Reject all overlong UTF8 sequences."
},
{ "name": "Stephen Dolan", "message": "Fix various UTF8 parsing bugs.\n\nIn particular, parse bad UTF8 by replacing the broken bits with U+FFFD\nand resychronise correctly after broken sequences."
},
{ "name": "Stephen Dolan", "message": "Fix example in manual for `floor`. See #155."
},
{ "name": "Nicolas Williams", "message": "Document floor"
}]我们可以看到,只要在上一步的命令中内容的两端加个中括号即可。
最后,我们如果想获取每个评论的引用评论的url(在parents节点中,有一个或多个)呢?
jq '[.[] | {message: .commit.message, name: .commit.committer.name, parents: [.parents[].html_url]}]'结果:
[
{ "parents": [ "https://github.com/stedolan/jq/commit/54b9c9bdb225af5d886466d72f47eafc51acb4f7", "https://github.com/stedolan/jq/commit/8b1b503609c161fea4b003a7179b3fbb2dd4345a"
], "name": "Stephen Dolan", "message": "Merge pull request #162 from stedolan/utf8-fixes\n\nUtf8 fixes. Closes #161"
},
{ "parents": [ "https://github.com/stedolan/jq/commit/ff48bd6ec538b01d1057be8e93b94eef6914e9ef"
], "name": "Stephen Dolan", "message": "Reject all overlong UTF8 sequences."
},
{ "parents": [ "https://github.com/stedolan/jq/commit/54b9c9bdb225af5d886466d72f47eafc51acb4f7"
], "name": "Stephen Dolan", "message": "Fix various UTF8 parsing bugs.\n\nIn particular, parse bad UTF8 by replacing the broken bits with U+FFFD\nand resychronise correctly after broken sequences."
},
{ "parents": [ "https://github.com/stedolan/jq/commit/3dcdc582ea993afea3f5503a78a77675967ecdfa"
], "name": "Stephen Dolan", "message": "Fix example in manual for `floor`. See #155."
},
{ "parents": [ "https://github.com/stedolan/jq/commit/7c4171d414f647ab08bcd20c76a4d8ed68d9c602"
], "name": "Nicolas Williams", "message": "Document floor"
}]这里用 .parents[].html_url 获取当前项的 parents 节点中的所有项的 html_url 属性的内容,然后两边加个中括号组装成数组输出。
jq能处理的需要是严格的JSON格式数据,JSON对象和JSON字符串是不行的,如下面的两种格式数据jq是不能处理的:
json对象:
{
a: 1,
b: {
c: "abc"
}
}json字符串:
'{"a":1,"b":{"c":"abc"}}'正确的JSON格式:
{
"a": 1,
"b": {
"c": "abc"
}
}