
对于acm新人来说,大家觉得最诡异的就是一道题同样的代码,用g++过了,换成c++死活不过。更诡异的是返回的却是wa而不是re。对于这种情况,新人们肯定会吐槽一下。这里我来总结一下其中几点缘由。
大的原因有三个,一个是代码本身存在越界情况,二是代码使用了过多的栈空间,三是代码中关于浮点数的处理有问题。这里主要解释前两种情况,第三种情况资料较多,不解释了。
对于情况一,先上一段代码
#include int main()
{
int a=1, c=2, b[5],t[10], i;
printf("%x,%x,%x\n",b,&c,&a);
for (i=0; i<=6; i++)
{
b[i] = i;
printf("%d ",b[i]);
}
printf("\na=%d,c=%d\n",a,c);
return 0;
}这段代码你会发现a c 的值都变了。一眼就能看出,for循环越界了。如果输出一下a b c的指针值,即在return 0前面加一个printf("%d %d %d",&a,b,&c);你会发现codeblocks下输出如下:
2686744 2686720 2686740
可以发现a c的地址相邻,因为他们的地址相差4(int占4字节),b最后定义却地址最小。讲地址相减发现,b和c之间只差5个int,此时假如越界发生,访问了b[5]空间,那么其实是访问的c变量。这就解释了c为什么是个5的原因,同理a为6。
那
么为什么b后定义结果地址却比a
c小呢,原因跟编译器有关,不同的编译器有不用的实现,计算机中大量的使用了队列和栈,他们的特性不再细说,编译器在进行编译时,会进行词法语法分析,此
时使用栈的话,代码生成趟时是先为b分配了内存地址,因为他在栈顶。不同系统之间内存分配的方式不同,有从高地址开始有从低地址开始,这也决定了内存地址
会在不同环境下而不同。
那么为什么既然越界了,给出的不是re而是wa呢。原因跟操作系统的内存保护有关,操作系统有个东西叫界地址寄存器,你的程序是一个段,有一个开始地址和一个长度,在寻址时(从程序的逻辑地址换到物理地址)首先与界地址寄存器检查是否越界,越界即会产
生中断。有时你的越界不太严重,越界之后的逻辑地址依旧在这个段之内,与界地址寄存器比较不越界,那么程序继续。假如上面的例子你把for的<=6
改为<=11你就会发现程序弹窗提示出错了。这意味着跑偏太远了。
另举一例说明编译器之间的差别。对于初学c的同学,上机使用的都是vc,最诡异的莫在于满屏幕的“烫”字。原因在于vc对于栈区的空间,会以0xCC填充,假如你输出了没有\0结尾的字符数组(数组是 在栈区),那么就会是一堆的烫(中文占两个字节,两个cc连在一起刚好是烫)。另一个诡异字符是“屯”,他的出现是因为你使用了new 或者melloc来动态申请内存,这个内存是在堆区,vc以0xCD填充,刚好是个屯。读者老爷可以试试在codeblocks下这些情况是否会发生,以验证编译器之间的差别。下面是一段代码以及在VC6下的运行结果
#include<cstdio>
int main () {
char str1[4];
char str2[2];
char *str3 = new char[4];
str1[0] = str2[0] = str3[0] = 'a';
str1[1] = str2[1] = str3[1] = 'b';
printf("%s\n%s\n%s\n", str1, str2, str3);
return 0;
}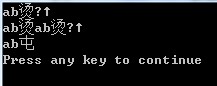
可以看到第二行后半部分其实是重复了第一行,因为他们的内存是紧邻的。
下面解释第二种情况,使用了过多的栈空间。有些题目比如搜索或者树形DP线段树等, 递归深度或者内存要求比较大,就会发现,当你用g++提交时总是re,但是c++可以通过。这也是由于编译器的不同,内存分配的差异和递归的实现方式,编 译器消耗的内存也是不同的,当栈区消耗完,在提出申请时,就会re。栈空间是比较宝贵的,应该节约着用,大的数组最好做成全局的,全局变量是存在全局区 的。读者老爷可以在main函数中开一个千万级的数组,运行会发现报错,但是将数组挪到全局变量,就能正常使用。具体那些变量在那些区,就不多说了。
以上内容读者老爷意会着看就行了,匆忙写的,错误不少,欢迎指正。